
初めまして。株式会社カミナシPMの@gtongy1です。
Dockerというツール。SRE, Backend, Frontendどの領域のエンジニアも馴染みのあるツールではないでしょうか。
コンテナを利用することにより、インフラの環境を一つの空間に梱包し、その内部で柔軟に様々な環境を作ることが出来ます。
コンテナの実体とはなんなのでしょう? 叡智が詰め込まれたそんな一つの宝箱のように見えます。
「 コンテナ作ってみたくなりませんか? 」
僕と同じように知的好奇心をくすぐられたそこのあなた!コンテナ沼の一歩目を一緒に踏み出してみましょう!
検証環境
Dockerの機能おさらい
まず、ドキュメント内を読み進めてDockerに対する知識を整理します。
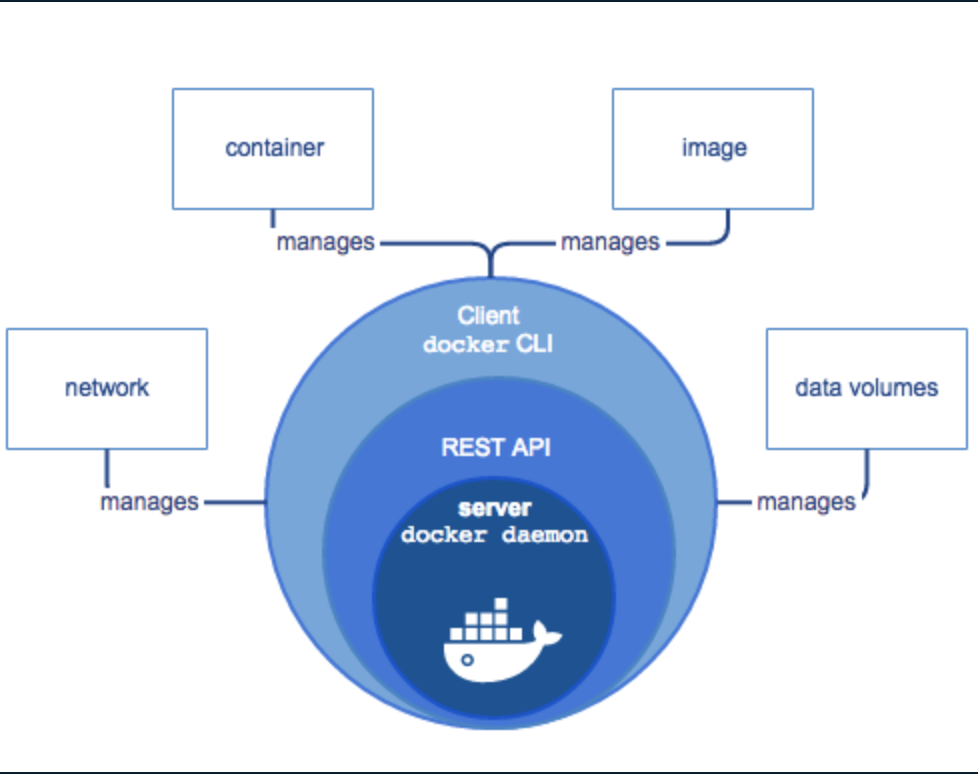
DockerはDocker daemonを基幹とし、その呼び出しを行うREST API, Docker Cliと機能が覆い被さっています。
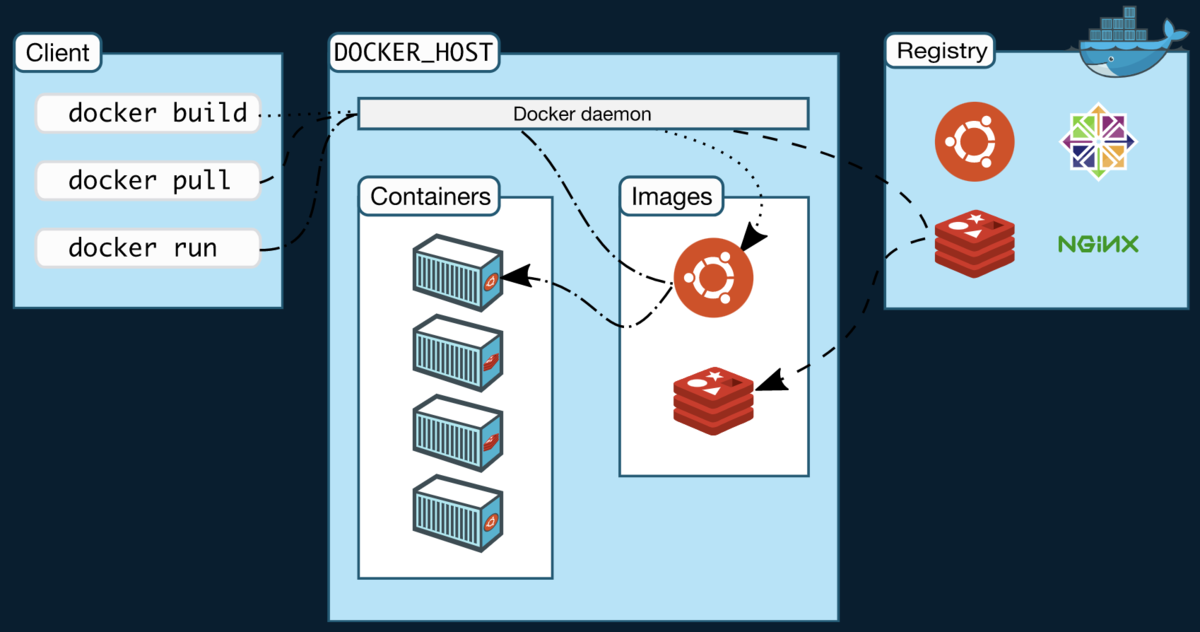
普段Cli経由で処理を行う、network, container, image, volumesはCli経由からこのDocker daemonの機能の呼び出しを行います。
RegistryからImageを取得し、ローカル内のImageをベースにコンテナを作成する部分は上記の図のようなイメージで呼び出されています。
そうなると気になるのは、Docker daemon。この内部の処理に全てのエッセンスが詰まっているように思われます。
Docker daemon内で動作しているのは、Linuxカーネルの基本となる機能群。
そこでLinuxのコンテナ周りに必要な機能の詳細、そして最小のコンテナを作って説明していきます。
Linux上にコンテナを呼び出し
大前提として、コンテナとは何者なのでしょうか。
コンテナを一言で言うと「 システムから分離されたプロセス 」です。
Linux上でunshareコマンドを打つことにより、最速でコンテナを作成することが出来ます。
※ 以降のコマンドはLinux上で実行しています。
$ unshare -u /bin/bash
$ hostname newhost && hostname
newhost
上記を実行することで、以下のようにプロセスが別に立ち上がっていることがわかります。
別のセッションでhostnameを実行してみましょう。
コンテナの誕生です🎉!これであなたも自作でコンテナを作ったと言っても良いでしょう!おめでとう!
この立ち上がったプロセスこそがコンテナであり、この内部で動く技術こそがDockerの基幹の技術なのです。
Linux、コンテナ3種の神器
上記のコンテナの内部ではどのようにして、プロセスの立ち上がったのでしょうか。
これはLinux内に備わったコンテナに必要な3種の神器である、
- Namespace
- Control Group
- File System
が関係しています。一つずつ説明していきましょう。
Namespace
Namespaceはコンテナ上に隔離された層を作成することが出来ます。
同一のカーネル上に別々の環境を作成するために、一意な名前を付けることによって別の環境であることを示すための機能こそがNamespaceです。
ネットワーク, 通信, ファイルマウント等処理を行う様々なプロセスはそれぞれでNamespaceを持っており、上記はunshareはプロセスを分離させNamespaceを作成しました。
Docker上でも同じようにNamespaceを活用しており、以下の種類があります。
- pid: プロセスID。システム内での一意なことを表すID
- net: ネットワークの管理
- ipc: プロセス間通信の管理
- mnt: ファイルシステムマウント管理
- uts: バージョン識別子, カーネルの管理
立ち上げたコンテナに上記のようなNamespaceを利用することによって、プロセスを分離して各機能を利用することが出来ます。
Control Group(cgroup)
Control Groupはアプリケーションを特定のリソースセットに制限します。
以下コマンドを実行してみて、内部にファイルとして置かれているものがControl Groupです。
$ cat /sys/fs/cgroup/cpuset/cpuset.cpus 0-3
Control Groupを使用すると、オプションで制限や制約を強制することができます。
メモリの最大利用数や、プロセス最大実行数などそれぞれです。
以下のようなファイルによって、制限を付与することが出来ます。
File System
子プロセスが親からマウントされたFile Systemに関するデータのコピーを取得し、親と同じデータ構造へのポインタを取得して変更できるように出来ます。
$ cat /proc/mounts
システム内でマウントされている情報をファイルから情報を読み解くことが出来ます。
proc /proc proc rw,nosuid,nodev,noexec,relatime 0 0 tmpfs /dev tmpfs rw,nosuid,size=65536k,mode=755 0 0 devpts /dev/pts devpts rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=666 0 0 sysfs /sys sysfs ro,nosuid,nodev,noexec,relatime 0 0 tmpfs /sys/fs/cgroup tmpfs ro,nosuid,nodev,noexec,relatime,mode=755 0 0 cpuset /sys/fs/cgroup/cpuset cgroup ro,nosuid,nodev,noexec,relatime,cpuset 0 0 cpu /sys/fs/cgroup/cpu cgroup ro,nosuid,nodev,noexec,relatime,cpu 0 0
このように、Namespaceを利用し、File System, Control Groupを活用することで稼働するコンテナに対して制約を設け、必要なファイル群をマウントし、コンテナの型を作ることが出来るようになります。
Go言語コンテナ始めの一歩
それでは、Go言語を使って実装していきましょう!
// +build linux package main import ( "fmt" "os" "os/exec" "syscall" ) func main() { switch os.Args[1] { case "run": run() default: panic("help") } } func run() { fmt.Printf("Running %v \n", os.Args[2:]) cmd := exec.Command(os.Args[2], os.Args[3]...) cmd.Stdin, cmd.Stdout, cmd.Stderr = os.Stdin, os.Stdout, os.Stderr cmd.SysProcAttr = &syscall.SysProcAttr{ Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS, } must(cmd.Run()) } func must(err error) { if err != nil { panic(err) } }
まず始めに環境内で引数から渡されたコマンドを実行するまで作成します。
syscall.SysProcAttrとそのフラグのうちでCloneflagsを追加しています。
これは新規のプロセスに対して新しいNamespaceを追加することが出来ます。
これによって、今回のUTS(UNIX Time Sharing), PID, NS(mount周り)を新しいnamespaceで作成しています。
$ go run exec.go run echo hello Running [echo hello] hello
上記ファイルを引数を渡し実行すると、内部でコマンドが実行していることがわかると思います。
次はコンテナを子プロセスとして立ち上げてみてみましょう。
func main() { switch os.Args[1] { case "run": run() case "child": child() default: panic("help") } } func run() { cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...) // ... } func child() { fmt.Printf("Running %v \n", os.Args[2:]) cmd := exec.Command(os.Args[2], os.Args[3:]...) cmd.Stdin, cmd.Stdout, cmd.Stderr = os.Stdin, os.Stdout, os.Stderr must(syscall.Sethostname([]byte("container"))) must(syscall.Chroot("/")) must(os.Chdir("/")) must(syscall.Mount("proc", "proc", "proc", 0, "")) must(cmd.Run()) must(syscall.Unmount("proc", 0)) }
ここで変更を加えているポイントとして
- childの関数を用意し、これまでと似たような関数を用意している。今までと比較して変更している点は以下
- Chroot
- syscall.Mount
- /proc/self/exe
のあたりが主に変わっているところでしょう。
今回の実装内で新規でchild関数を用意し、その内部でこれまでと同じようにプロセスを立ち上げ、syscall.Sethostnameで新しく立ち上げたプロセスにホスト名を付与しています。
また新しく立ち上げたプロセスに対して、syscall.Mount,Chrootを利用し子プロセスの設定を追加しています。
chrootは、子プロセスのルートの指定、syscall.Mountはファイルのマウントを行う処理です。
上記実装により、新しく立ち上げたプロセスに親プロセスの情報を追記することや、ディレクトリの構成を指定することが出来ています。
また、親プロセス内で実行している、/proc/self/exeは今実行しているプロセスを再実行します。この時の第一引数としてchildを渡しています。
よって、親プロセス内部で子プロセスを呼び出し、処理を実行することが出来ます。
それでは実行してみましょう。
root@24b10018b09a:/go# go run main.go run /bin/bash Running [/bin/bash] Running [/bin/bash] root@container:/#
上記のようにプロセスが2つ実行され、hostnameがcontainerに変換されているのがわかります。
子プロセスの立ち上げと、その内部でプロンプト上で操作することができました!
Control Groupの作成
最後にControl Groupを追加していきます。
func child() { // ... setControlGroup() } func setControlGroup() { cgroups := "/sys/fs/cgroup/" pids := filepath.Join(cgroups, "pids") must(os.Mkdir(filepath.Join(pids, "gtongy"), 0755)) must(ioutil.WriteFile(filepath.Join(pids, "gtongy/pids.max"), []byte("20"), 0700)) must(ioutil.WriteFile(filepath.Join(pids, "gtongy/notify_on_release"), []byte("1"), 0700)) must(ioutil.WriteFile(filepath.Join(pids, "gtongy/cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700)) }
Control Groupはファイル群です。
立ち上げた子プロセスのpidを設定に登録、このグループ内にその他の制約を設けています。
ここで上げているのはpids.maxで、設定したプロセスに対して最大数を設けています。
ここに追加でmemoryの制限や、CPUのリソースの制約を追加することも出来ます。
コードサンプル
最後にコードサンプルです。一連の流れを追うためにご活用ください。
終わりに
コンテナ作成の一連の流れを説明、またGo言語を利用してコンテナ化を行いミニDockerを作成してみました。
一連の流れを追い、小さい単位でスクラッチで機能を作成することが深い理解に繋がると思います。
こうして、自作で今まで難しいと思っていた機能を紐解いてみるとワクワクしませんか!
自分の知らなかった世界の広がりと、今動いているシステムの良さや改善できそうなところが滲み出てくる感覚がします。
そんな自作コンテナ沼。一緒に今年の年末年始のあいた時間に遊んでみてはいかがでしょうか。
最後に宣伝です。
カミナシでは上記のようなコンテナをAWS Fargateを利用し、本番環境で元気に動かしています。
そんな環境で、柔軟なインフラ作ったりアプリを成長させたりチャレンジしてみたい熱量持ったエンジニアの方を募集しています。
エントリーお待ちしております!!