初めまして。株式会社カミナシPMの@gtongy1です。
みなさんは、インフラのコンテナ化はお済みでしょうか?
弊社は今年6月頃にサービスを正式にリリースしたのですが、それ以前はEC2 + ELBでインフラを構築しており、それまでになかなかコンテナ化をしたくても出来ない状態でした。
各社様々な背景はあると思いますが、自分は
- コンテナ化をすればいいのは、なんとなくわかる。ただ、どこから始めたらいいんだろうか
- EC2構成でも動いているがために、なかなか変えようとする一歩目が踏み出せない
- コンテナ化を本番環境で構築した経験がない。実際にどんなことが課題として上がるんだろうか
あたりに不安を感じていました。
ただ、インフラ運用に事業の足を取られてしまうリスクを抱える、それが嫌でコンテナ化を今回行いました。
そんな中での取り組みや課題感を先日話してきたので、その詳細をお伝え出来ればなと思います。
発表資料
そもそもの構成(EC2 + ELB)の課題感
サービス初期は、以下のような構成で開発を行っていました。

よくあるEC2 + ELBの冗長化構成を取っていたのですが
- EC2へ直接scpでバイナリコピーを行う
- CI上でバイナリを挿げ替えるタイミングで一時的にダウンタイムが発生してしまう
- EC2内のミドルウェア(fluentd, systemdなど)がブラックボックス化
- 外部サービスへの繋ぎこみの難易度の高さ、インフラの壊しにくさ
の課題感にぶつかりました。
EC2を利用している方は馴染みのある課題感だと思いますが、弊社も例外ではなく同じような課題に悩まされていました。
立ち上げ期/検証のフェーズのため、インフラそのものを止めたとしてもリクエストも多くなく、障害となることも当時は少数でした。
ただ、今後のサービスの安定性を担保するフェーズにおいて、インフラそのもの柔軟性が下がるとどうか。
将来のコストを暗黙的に増大させることになる未来が想像出来ます。
なるべく初期のタイミングで、インフラの足回りを整えることは開発のサイクルを高速で回すためにも必要なコスト!と割り切り、移行へと黙々と取組みました。
コンテナ化後のインフラ構成
コンテナ化後は以下のような構成を取っています。

golangで吐き出したシングルバイナリを起動するalpine linuxのコンテナをFargate上で起動し、その他のミドルウェアに関連するコンテナをサイドカーパターンで別で切り分けるようにしています。

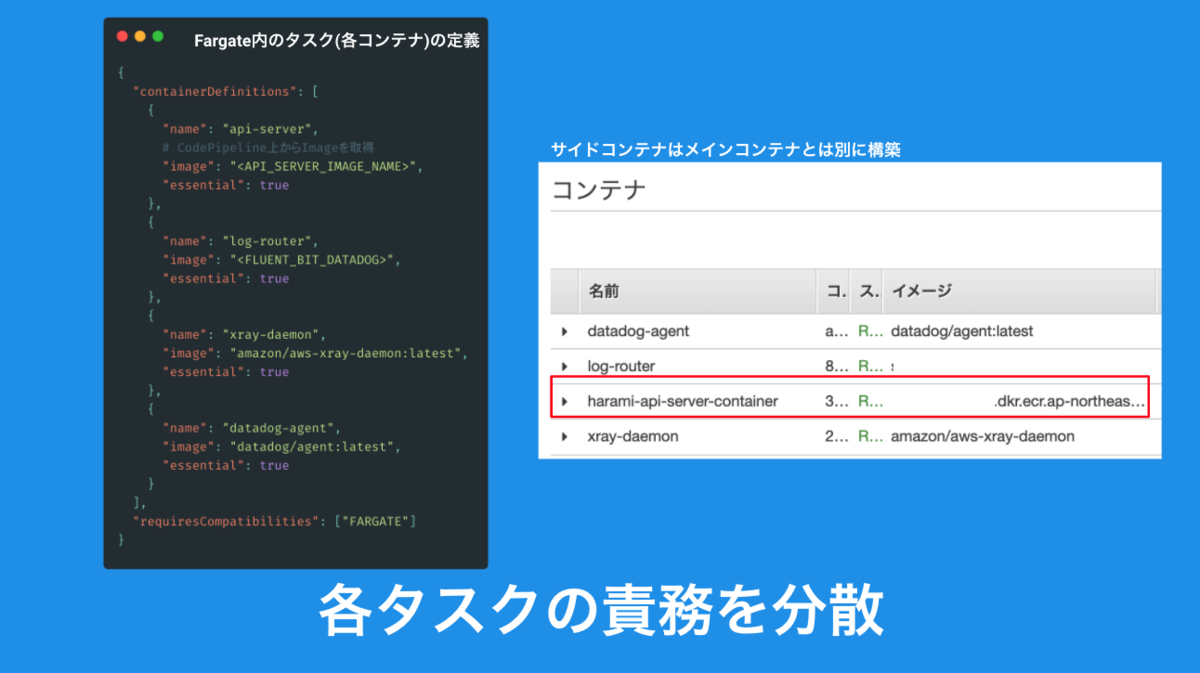
メインコンテナとはまた別のユニットとして立ち上げるため、仮にサイドカーで立ち上げたコンテナにエラーが発生した時にもメインコンテナ内への影響はなく動作するところがメリットです。
またサイドカー形式で立ち上げる時に、ログ周りのメリットも大きくてAWS側のfirelensを利用することが出来ます。
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/using_firelens.html
firelensは、サイドカーで立ち上げているFluentdもしくはFluent Bitに対してログを流し込むことが可能となるルーティングの設定です。
{ "containerDefinitions": [ { "name": "log_router", "essential": true "logConfiguration": { "logDriver": "awsfirelens" } }, { "name": "api_server", "essential": true, "firelensConfiguration": { "type": "fluentbit", "options": { "config-file-type": "file", "config-file-value": "/fluent-bit/etc/extra.conf", "enable-ecs-log-metadata": "true" } } } ] }
APIサーバー側からfirelensを利用して、Fluent Bitへログを流しこみます。
ログだけを切り取ってみるとAPIサーバー側はどこにログを出力を行うか、Fluent Bit側は受け取ったログをどう取り扱うかに責務がうまく分けることが出来ます。
弊社はFluent Bit側の設定ではdatadogへログを流し込んでいるのですが、EC2の時はAPIサーバーにこの辺りの設定も書き込まれていたりしたので、この辺がとてもすっきりしました。
またCodePipelineで記述されているCI/CD周りはAWS CDKでIaC化し、壊しやすいインフラは積極的にコード化していきました。
この時に使ったformer2というものがとても便利。
CloudFormationだけでなく、AWS CDKにも使えたりするので実装時には結構重宝しました。
課題の探索
大枠のインフラの構成を作った後はひたすらテストですが、このあたりは負荷テストを行いながら課題を探索して行きました。
あたりの観点から、負荷テストの各項目に対して負荷をかけながら実際のエラーを測定してきました。 APM(AWS X-Ray)と統合監視ツール(Datadog Synthetic Monitoring)を使い分けしながら、実際の性能や単体ごとのケースを確認していきます。
性能テスト - スループット, 応答時間
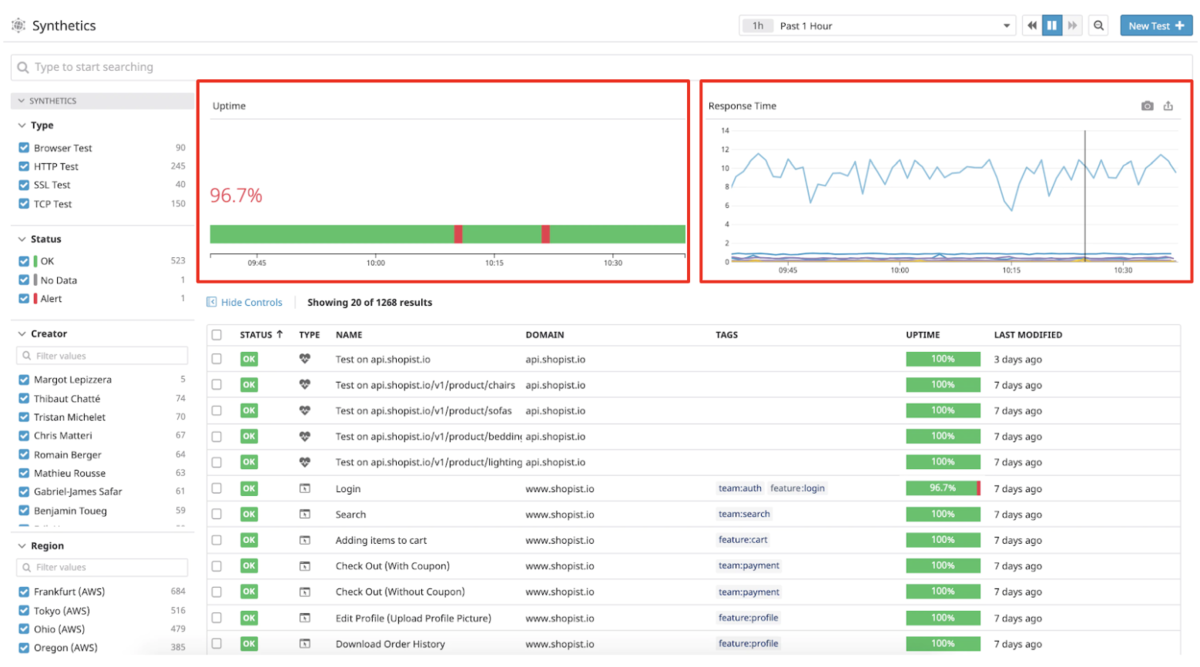
Datadog Synthetic Monitoringは各エンドポイントに対して想定されるパターンにリクエストを送信します。
この時、どのくらいのレスポンスタイムがかかるか、また想定通りのパラメータが返ってきたかを確認しながら判定を行います。
一度エンドポイントのテストを作成すればその後の運用も楽になるのもいいところ。
このあたりは先日まとめたので、気になる方は以下をご覧ください。
過負荷テスト, 長時間テスト, 障害テスト
過負荷をかけるテストに関してはvegetaを利用しています。

CLI経由から気軽に過負荷, 長時間のテストを実行できるのがいいところ。
また、レポートもhtmlで出力してくれるため、実際に負荷をかけて一つずつ課題を潰していくような流れでテストを行っています。
障害テスト周りでは、
- Auroraで立ち上がったDBのinstanceに対してfailoverさせてみる
- ECSのデプロイ時にRollBack
- ECS内のタスクを一つ削除
してみたりと、一つずつケースを潰す作業を行いながらテストを進めていきました。
起こった課題
- 各タスクのCPUの負荷が100%を超過するので、タスクのCPUの調整
- タスク内のlimit値の調整
- リクエスト数過多によるDead Lockの発生
- N+1問題の解決
- DBのConnection数の爆発
などなど。
負荷をかけてみることで改めて顕在化するようなデグレを地道に潰す作業です。
この負荷テストを行うまで自分は、golangのdatabase/sqlパッケージを利用して毎回Open/Closeしてました。ぽかミスすぎて恥ずかしい。
golangのdatabase/sqlパッケージは、ファイルのOpen/Closeとかとは違って毎回Open/Closeする必要はなく、ランタイム内で既存のconnectionを使い回すことを想定した作りになっています。
その設定の中で、SetMaxOpenConns, SetMaxIdleConns, SetConnMaxLifetimeを使い、コネクションの最大接続数/最大接続時間を制御します。
ここで急激にconnectionが増加してとても焦りましたが、X-Rayとか実際のRDBのログとかを追いながらエラー探しあてていました。

この辺りにツール使いながら、特定の箇所でのトレーシングを行えたり、接続数を見ながら負荷テストを行えたのもいいところですね。
まとめ
スタートアップが取り組むコンテナ化の例として、カミナシが取り組んできたインフラ移行の事例について紹介させていただきました。
今回やってみて思ったのは、えいやで変更する気概と動作テストがとにかく大事。ベストプラクティスは世の中に多く転がっていたりするので。
あとは課題に恐れず前に進めることで、とそのあとの運用が楽になる切符を手にすることが出来ます。
将来継続的に事業障害となる箇所を未然に防ぐため、未知なものの投資を積極的に行っていきましょう!
最後に宣伝!!
カミナシではこんな感じで、日々技術の課題も現場の課題も山積みです。どちらもメンバー全員で共に山に登っている真っ最中です。
そんな環境で、チャレンジしてみたい熱量持ったエンジニアの方を募集しています。エントリーお待ちしております!!